原文转载于 https://mp.weixin.qq.com/s/ia0MKR6vYd5XNuWkw8iegQ 2021-12-22
随着音乐人工智能研究的逐步深入,缺乏高质量的海量音乐数据已经成为制约研究发展的重要问题,寻找“量化”音乐的标准也成为研究关键。近日,由上海市音乐声学艺术重点实验室牵头组建的音乐人工智能数据项目组,历尽数月的研发,发布了SoundIn Xml数据标准以及上线专用网站www.soundin.org

当前人工智能技术在音乐中的研究已经深入到各个方面,人工智能从要素上来看包括算力、算法、数据和应用场景四个要点。从音乐的应用场景上来说,可以包括音乐生成,音乐分析、音乐教育等多个方面。这些场景中目前研究的普遍共识都是建立在监督学习的基础上的,这决定了数据是整个研究的基础,音乐数据作为机器学习的“原料”的重要性越发凸显。
与其他学科相比,音乐领域的数据种类繁多,不确定性强,标准不统一,标注成本高,这些问题阻碍了相关技术的发展。所以,什么样的数据是高质量的数据,如何获得高质量的数据,是目前急需优化和解决的问题。音乐研究所需的数据有以下几个主要特点。
1.种类繁多。音乐从理解,分析到生成等过程中环节很多,所以对应的数据类型和特征的维度也非常多。
2.标注难度大。针对音乐数据的标注需要相当水准和数量的音乐专业从业人员,这也间接造成制作数据的难度大,成本高。
3.缺乏较好的数据标准。音乐作为一门比较抽象的艺术,很多规则和特征难以量化,相应的数据标准也比较难制定,所以目前科研界所用的数据标准也不统一。
同时,在音乐人工智能研究过程的不同层级中,时刻都体现着数据的重要性。
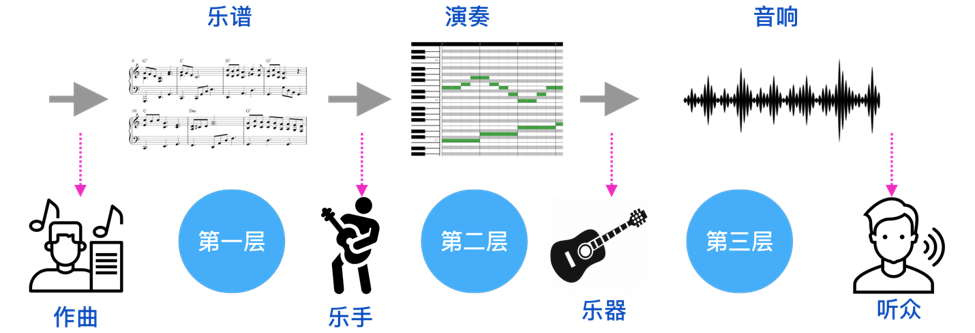
理想的音乐数据应该有以下特点:
第一,数据要方便计算机来处理,文本符号形式是最优的选择之一,但是需要有配套的回放系统和标准配合。常用的文本信息需要包含拍号、速度、小节、位置、乐器、音高、时长、速度等。在表示的规则中,需要最大限度的地缩短音乐序列长度,还要容纳足够的音乐信息。更短的序列长度可以提高模型处理音乐片段的效率,最终提高机器对音乐的理解能力。
第二,数据集应该提供可扩展的标签,以应对不同研究的需求。这些注释不仅为音乐生成提供信息,而且有利于乐谱和表演信息之间的转换。
第三,数据集的规模要足够大并且质量要高。深度学习模型通常需要大的样本量,效果才能更好。标注的准确程度和品质将会决定模型最终的效果。但收集更多数据需要更多的成本,最好的解决方案是,设计的数据方式最好与已有的数据有较好的兼容性,这样可以尽可能在已有数据上进行优化而不是重新制作,从而降低成本。
第四,数据和时间轴的对应要十分直观并方便编辑和显示。比如结构、和弦以及注释等要与时间对齐。最好的方式需要有一个配套的标注软件工具,才能提高制作效率,降低标注人员的工作量。
为解决上述问题,项目组开发SoundIn Xml的音乐数据表征方式,并研发相关的配套工具和程序。
首先,SoundIn Xml采用可扩展标记语言的格式,利用了文本方式的优点,同时利用一种树状的数据结构,方便转换。
这种方式还可以方便的与MIDI等格式相互转化,这样就可以保证解析简单,编辑方便,表达准确,可以利用历史上已有的大量MIDI文件,为后续产生大量的优质数据奠定基础。
此外在特定音乐制作软件中,通过时间轴的标记轨道,可以方便的与波形文件对应,既可以形成音频和文本的综合型文件,以适用于音频层面研究。
最终构建的SoundIn Xml数据文件部分内容如下:
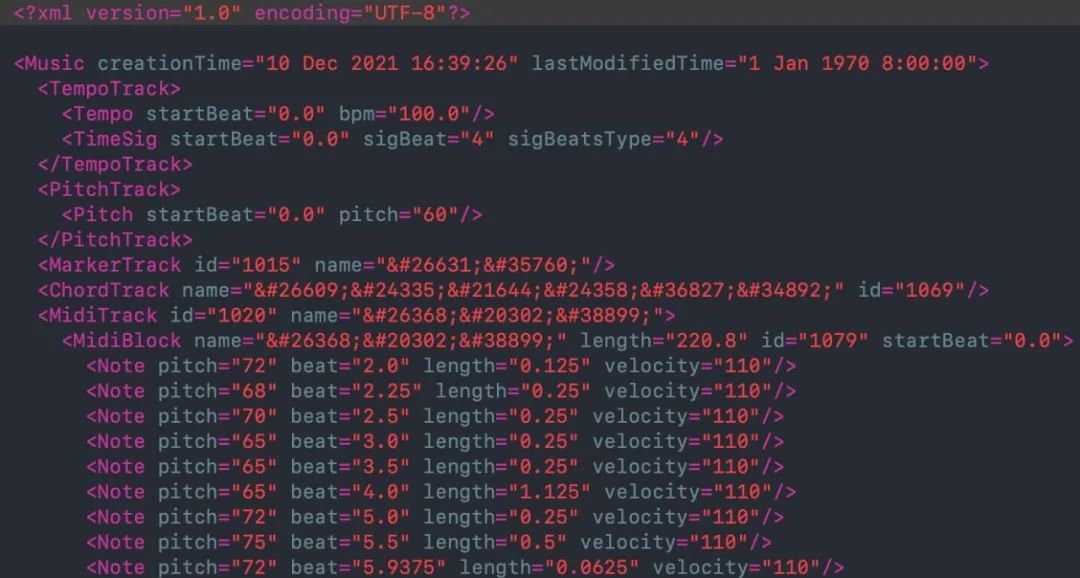
具体数据说明详情请登陆网站查看。目前,网站上已提供数千首xml和配套的midi文件提供免费下载,更多的数据正在制作过程中。
如果您想参与该项目,也可以联系我们,并在网站上提交数据,我们将审核后发布。
如果想快速的制作这种数据,可以联系我们,获得专用版的SoundBug软件,在界面上直接编辑好后导出,这样可以大大加快制作标注效率,检查的时候也更加直观。

您也可以通过Cubase等软件,对指定轨道的信息导出xml文件,不过这种xml并不符合soundin xml的标准,需要在代码中再次转换。
近年来,项目组也积极组织音乐工程系,数字媒体学院的学生等参与一起,与微软人工智能创造实验室合作,为“小冰”人工智能音乐模型制定数据标准和标注数据。其中包括制定对乐汇、和弦、乐段以及其他音乐元素的筛选规则等等,并完成数千首歌曲数据的清洗和标注。此外正在进行的工作包括与科大讯飞公司讯飞音乐部门,开展针对音乐创作人的音乐推荐算法研究,与华为BG音频事业部探讨音频音响的量化标准等等。在这些研究和应用中,我们也在不断升级和完善SoundIn Xml标准,希望能进一步丰富各种音乐元素的标签,增加量化音乐的维度。


音乐工程系数据标注项目学生讨论会
欢迎更多的研发人员下载数据用于研究,也欢迎更多的音乐从业人员参与数据的制作并上传数据。






